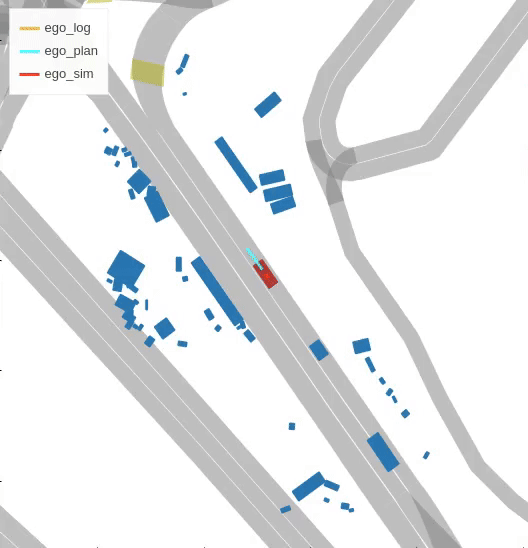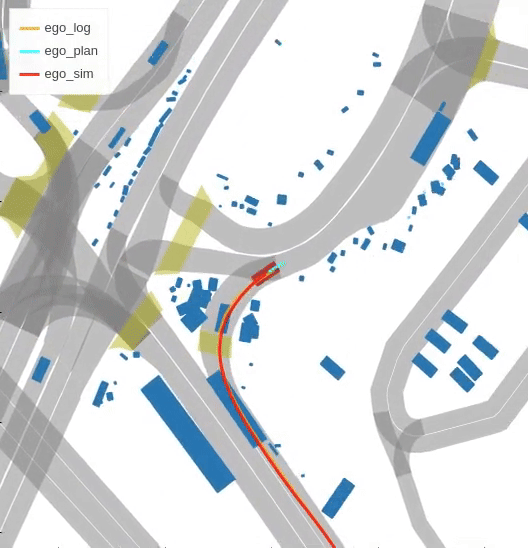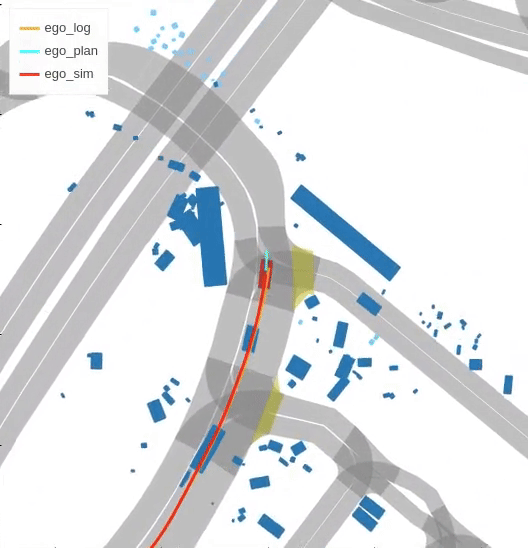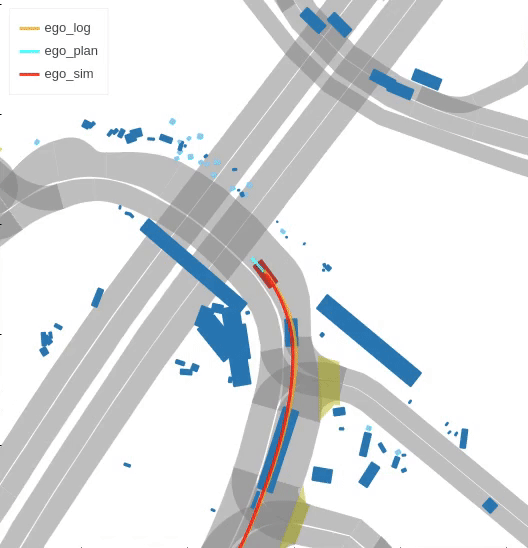
 Closed-loop simulation
Closed-loop simulation
Imitation learning holds great promise for addressing the complex task of autonomous urban driving, as experienced human drivers can navigate highly challenging scenarios with ease. While behavior cloning is a widely used imitation learning approach in autonomous driving due to its exemption from risky online interactions, it suffers from the covariate shift issue. To address this limitation, we propose a context-conditioned imitation learning approach that employs a policy to map the context state into the ego vehicle’s future trajectory, rather than relying on the traditional formulation of both ego and context states to predict the ego action. Additionally, to reduce the implicit ego information in the coordinate system, we design an ego-perturbed goal-oriented coordinate system. The origin of this coordinate system is the ego vehicle’s position plus a zero mean Gaussian perturbation, and the x-axis direction points towards its goal position. Our experiments on the real-world large-scale Lyft and nuPlan datasets show that our method significantly outperforms state-of-the-art approaches.
Ke Guo
PhD of Artificial Intelligence
I draw ideas in optimization, control and artificial intelligence to develop algorithms for autonomous driving and intelligent transportation.